

Le bord saignant: Au fur et à mesure que la technologie deepfake évolue, il devient de plus en plus difficile de savoir quand une vidéo a été manipulée. Heureusement, divers groupes ont développé des réseaux de neurones sophistiqués pour détecter les faux visages. Cependant, les informaticiens ont révélé la semaine dernière qu’ils avaient un moyen de tromper même les modèles de détection les plus robustes en leur faisant croire qu’un deepfake est réel.
Des chercheurs de l’Université de Californie à San Diego ont développé une technique qui peut tromper les algorithmes formés pour détecter les vidéos deepfake. En utilisant une méthode en deux étapes, les informaticiens prennent un deepfake détectable puis le fabriquent et insèrent une couche « d’exemple contradictoire » dans chaque image pour créer un nouveau faux qui est pratiquement indétectable.
Les exemples contradictoires sont simplement des images manipulées qui encrassent un système d’apprentissage automatique en le faisant reconnaître une image de manière incorrecte. Un exemple de cela que nous avons vu dans le passé sont les autocollants antagonistes ou même le ruban isolant utilisé pour inciter les véhicules autonomes à mal interpréter les panneaux de signalisation. Cependant, contrairement à la dégradation des panneaux de signalisation, la méthode UCSD ne change pas l’apparence visuelle de la vidéo résultante. Cet aspect est significatif puisque le but est de tromper à la fois le logiciel de détection et le spectateur (voir vidéo ci-dessous).
Les chercheurs démontré deux types d’attaques: «White Box» et «Black Box». Avec White Box exploits, le mauvais acteur sait tout sur le modèle de détection ciblé. Les attaques Black Box se produisent lorsque l’attaquant n’a pas connaissance de l’architecture de classification utilisée. Les deux méthodes «sont robustes aux codecs de compression vidéo et d’image» et peuvent tromper même les systèmes de détection les plus «à la pointe de la technologie».
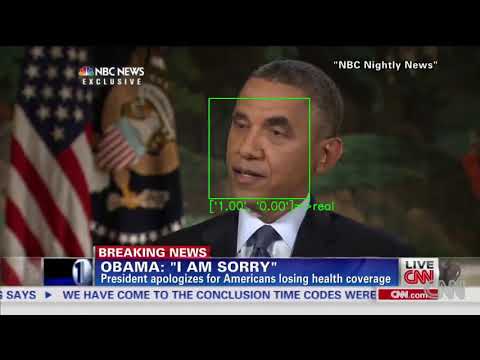
Les Deepfakes ont suscité pas mal de controverses depuis leur apparition sur Internet il y a quelques années. Au début, c’était principalement des célébrités indignées par leur apparence dans des vidéos porno. Cependant, au fur et à mesure que la technologie s’améliorait, il est devenu clair que les mauvais acteurs ou les nations voyous pouvaient l’utiliser à des fins de propagande ou à des fins plus néfastes.
Les universités ont été les premières à développer des algorithmes pour détecter les deepfakes, suivies rapidement par le département américain de la Défense. Plusieurs géants de la technologie, dont Twitter, Facebook et Microsoft, ont également développé des moyens de détecter les deepfakes sur leurs plates-formes. Les chercheurs affirment que la meilleure façon de lutter contre cette technique est d’effectuer une formation antagoniste sur les systèmes de détection.
«Nous recommandons des approches similaires à la formation contradictoire pour former des détecteurs Deepfake robustes», a expliqué le co-auteur Paarth Neekhara dans le document de recherche de l’équipe. « C’est-à-dire qu’au cours de l’entraînement, un adversaire adaptatif continue de générer de nouveaux Deepfakes qui peuvent contourner l’état actuel du détecteur et le détecteur continue de s’améliorer afin de détecter les nouveaux Deepfakes. »
Le groupe posté plusieurs exemples de son travail sur GitHub. Pour ceux qui s’intéressent aux détails de la technologie, consultez le papier publié via arXivLabs de Cornell.







