

Parmi les innovations qui alimentent l’open source populaire TensorFlow apprentissage automatique sont la différenciation automatique (Mise à niveau automatique) et l’ XLA (Algèbre linéaire accélérée) compilateur d’optimisation pour apprentissage profond.
Google JAX est un autre projet qui réunit ces deux technologies, et il offre des avantages considérables pour la vitesse et la performance. Lorsqu’il est exécuté sur des GPU ou des TPU, JAX peut remplacer d’autres programmes qui appellent NumPy, mais ses programmes s’exécutent beaucoup plus rapidement. De plus, l’utilisation de JAX pour les réseaux neuronaux peut rendre l’ajout de nouvelles fonctionnalités beaucoup plus facile que l’extension d’un framework plus large comme TensorFlow.
Cet article présente Google JAX, y compris un aperçu de ses avantages et limitations, des instructions d’installation et un premier aperçu du démarrage rapide de Google JAX sur Colab.
Qu’est-ce qu’Autograd ?
Autograd est un moteur de différenciation automatique qui a commencé comme un projet de recherche dans le Harvard Intelligent Probabilistic Systems Group de Ryan Adams. Au moment d’écrire ces lignes, le moteur est maintenu mais n’est plus activement développé. Au lieu de cela, ses développeurs travaillent sur Google JAX, qui combine Autograd avec des fonctionnalités supplémentaires telles que la compilation XLA JIT. Le Moteur Autograd peut différencier automatiquement le code natif Python et NumPy. Sa principale application prévue est l’optimisation basée sur le gradient.
TensorFlow tf.GradientTape L’API est basée sur des idées similaires à Autograd, mais son implémentation n’est pas identique. Autograd est entièrement écrit en Python et calcule le dégradé directement à partir de la fonction, tandis que la fonctionnalité de bande de dégradé de TensorFlow est écrite en C++ avec un wrapper Python fin. TensorFlow utilise la rétropropagation pour calculer les différences de perte, estimer le gradient de la perte et prédire la meilleure étape suivante.
Qu’est-ce que XLA ?
XLA est un compilateur spécifique à un domaine pour l’algèbre linéaire développé par TensorFlow. Selon la documentation TensorFlow, XLA peut accélérer les modèles TensorFlow sans potentiellement aucune modification du code source, améliorant ainsi la vitesse et l’utilisation de la mémoire. Un exemple est un Google 2020 Soumission du benchmark BERT MLPerf, où 8 GPU Volta V100 utilisant XLA ont obtenu une amélioration des performances d’environ 7 fois et une amélioration de la taille des lots d’environ 5 fois.
XLA compile un graphe TensorFlow dans une séquence de noyaux de calcul générés spécifiquement pour le modèle donné. Étant donné que ces noyaux sont uniques au modèle, ils peuvent exploiter des informations spécifiques au modèle à des fins d’optimisation. Dans TensorFlow, XLA est également appelé compilateur JIT (juste-à-temps). Vous pouvez l’activer avec un indicateur dans le @tf.function Décorateur Python, comme ça:
@tf.function(jit_compile=True)
Vous pouvez également activer XLA dans TensorFlow en définissant l’option TF_XLA_FLAGS variable d’environnement ou en exécutant le module autonome tfcompile outil.
Outre TensorFlow, les programmes XLA peuvent être générés par:
Premiers pas avec Google JAX
Je suis passé par le Démarrage rapide JAX sur Colab, qui utilise un GPU par défaut. Vous pouvez choisir d’utiliser un TPU si vous préférez, mais l’utilisation mensuelle gratuite du TPU est limitée. Vous devez également exécuter un initialisation spéciale pour utiliser un TPU Colab pour Google JAX.
Pour accéder au démarrage rapide, appuyez sur la touche Ouvrir dans Colab en haut du bouton Évaluation parallèle dans JAX page de documentation. Cela vous permettra de basculer vers l’environnement de bloc-notes en direct. Ensuite, déposez le Relier dans le bloc-notes pour se connecter à un runtime hébergé.
L’exécution du démarrage rapide avec un GPU a clairement montré à quel point JAX peut accélérer les opérations d’algèbre matricielle et linéaire. Plus tard dans le cahier, j’ai vu des temps accélérés par JIT mesurés en microsecondes. Lorsque vous lisez le code, une grande partie de celui-ci peut vous rappeler comme exprimant des fonctions courantes utilisées dans l’apprentissage profond.
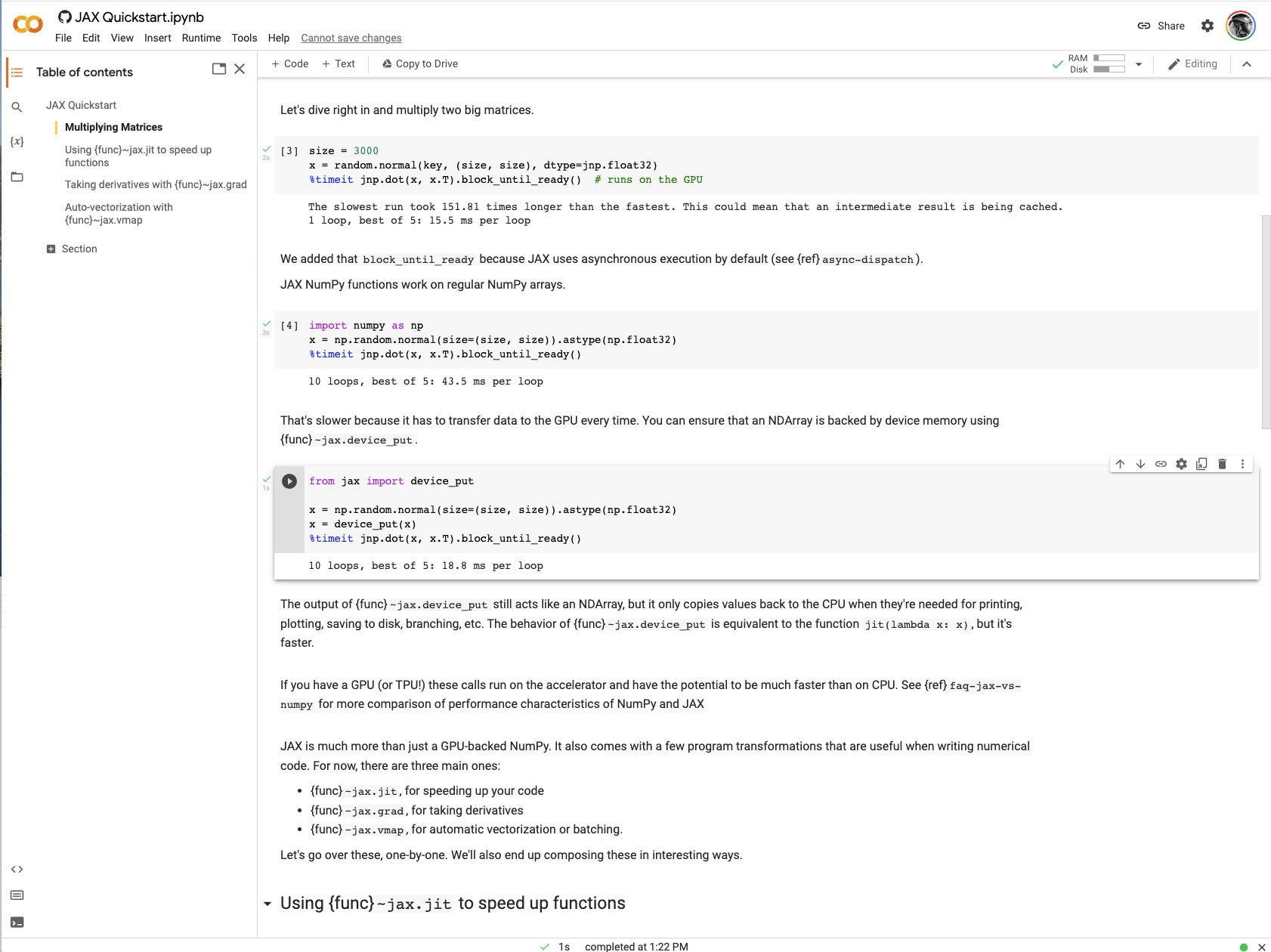 IDG
IDGGraphique 1. Exemple mathématique matricielle dans le guide de démarrage rapide de Google JAX.
Comment installer JAX
Une installation JAX doit être adaptée à votre système d’exploitation et à votre choix de cpu, GPU ou TPU. C’est simple pour les processeurs; par exemple, si vous souhaitez exécuter JAX sur votre ordinateur portable, entrez :
pip install --upgrade pip
pip install --upgrade "jax[cpu]"
Pour les GPU, vous devez avoir CUDA et CuDNN installé, avec un pilote NVIDIA compatible. Vous aurez besoin versions assez nouvelles des deux. Sous Linux avec des versions récentes de CUDA et CuDNN, vous pouvez installer des roues pré-construites compatibles CUDA; sinon, vous devez construire à partir de la source.
JAX fournit également des roues pré-construites pour Google Cloud TPUs. Les TPU Cloud sont plus récents que les TPU Colab et ne sont pas rétrocompatibles, mais les environnements Colab incluent déjà JAX et la prise en charge correcte des TPU.
L’API JAX
Il y a trois couches à l’API JAX. Au plus haut niveau, JAX implémente un miroir de l’API NumPy, jax.numpy. Presque tout ce qui peut être fait avec numpy peut être fait avec jax.numpy. La limitation de jax.numpy est que, contrairement aux tableaux NumPy, les tableaux JAX sont immuables, ce qui signifie qu’une fois créés, leur contenu ne peut pas être modifié.
La couche intermédiaire de l’API JAX est jax.lax, qui est plus stricte et souvent plus puissante que la couche NumPy. Toutes les opérations dans jax.numpy sont finalement exprimées en termes de fonctions définies dans jax.lax. Pendant que jax.numpy favorisera implicitement les arguments pour autoriser les opérations entre des types de données mixtes, jax.lax ne le fera pas; au lieu de cela, il fournit des fonctions de promotion explicites.
La couche inférieure de l’API est XLA. Tout jax.lax les opérations sont des wrappers Python pour les opérations dans XLA. Chaque opération JAX est finalement exprimée en termes de ces opérations XLA fondamentales, ce qui permet la compilation JIT.
Limites de JAX
Transformations et compilation JAX sont conçus pour fonctionner uniquement sur des fonctions Python qui sont fonctionnellement pures. Si une fonction a un effet secondaire, même quelque chose d’aussi simple qu’un print() , plusieurs exécutions à travers le code auront des effets secondaires différents. Un print() imprimerait différentes choses ou rien du tout sur les tirages ultérieurs.
D’autres limitations de JAX incluent l’interdiction des mutations sur place (car les tableaux sont immuables). Cette limitation est atténuée en autorisant les mises à jour de baies déplacées :
updated_array = jax_array.at[1, :].set(1.0)
En outre, JAX utilise par défaut des nombres de précision uniques (float32), tandis que NumPy utilise par défaut la double précision (float64). Si vous avez vraiment besoin d’une double précision, vous pouvez régler JAX sur jax_enable_x64 mode. En général, les calculs à précision unique s’exécutent plus rapidement et nécessitent moins de mémoire GPU.
Utilisation de JAX pour la mise en réseau neuronale accélérée
À ce stade, il devrait être clair que vous purent mettre en œuvre des réseaux de neurones accélérés dans JAX. D’autre part, pourquoi réinventer la roue ? Les groupes de recherche Google et DeepMind ont open-source plusieurs bibliothèques de réseaux neuronaux basées sur JAX: Lin est une bibliothèque complète pour la formation aux réseaux neuronaux avec des exemples et des guides pratiques. Haïku est pour les modules de réseau neuronal, Optax est destiné au traitement et à l’optimisation des gradients, RLax est pour RL (apprentissage par renforcement), et chex est destiné à un code et à des tests fiables.
En savoir plus sur JAX
En plus de l’ Démarrage rapide JAX, JAX a un série de tutoriels que vous pouvez (et devriez) exécuter sur Colab. Le premier tutoriel vous montre comment utiliser le jax.numpy fonctions, le grad et value_and_grad , et le @jit décorateur. Le didacticiel suivant approfondit la compilation JIT. Par le dernier didacticiel, vous apprenez à compiler et à partitionner automatiquement des fonctions dans des environnements à un ou plusieurs hôtes.
Vous pouvez (et devriez) également lire la documentation de référence JAX (en commençant par le FAQ) et exécutez les didacticiels avancés (en commençant par le Livre de recettes Autodiff) sur Colab. Enfin, vous devez lire la documentation de l’API, en commençant par le package JAX principal.
Droits d’auteur © 2022 IDG Communications, Inc.




